はじめに
先日、「言語研究者のための統計の学び方―基礎を身につける」という記事で、統計の基礎の学び方を紹介した。そこで紹介したことを学ぶだけでも、結構色々な言語研究ができる。だが、もう少し本腰を入れて言語研究をする場合は、統計に関して、より高度な内容を学んでおく必要がある。
今回は、統計の基礎を学び終えた言語研究者が次にどう勉強していけば良いかについて紹介する。
この記事で扱う内容
先日書いた「言語研究者のための統計の学び方―基礎を身につける」という記事では、統計の基礎をどう勉強すれば良いかについて触れた。今回は、より高度な内容を学ぶためにはどうすれば良いかについて紹介したい。図示すると、以下のとおりになるだろう。
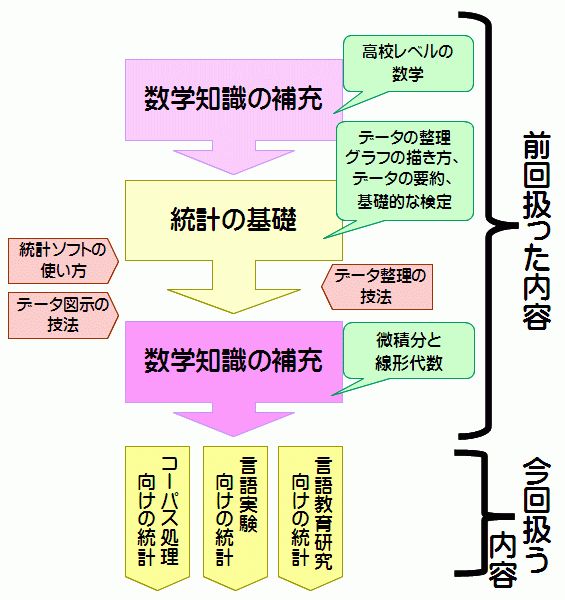
上に掲げた図からも分かるように、今回扱う内容は、「コーパス処理向け」・「言語実験向け」・「言語教育向け」の3つに分かれている。このように分けた理由は、分野によって統計との関わり方が違うからである。分野ごとにどう違うのかについては、先日記した「言語研究と統計の関係」という記事を参照されたい。なお、私の興味・関心の都合から、この記事では、大量のテキストデータ―特にコーパス―を使用する際の統計を中心としてみていきたい。もちろん適宜、言語実験や言語教育における統計に関しても触れるつもりである。
このレベルになると、言語研究者向けの教科書はなかなか無い。このため、一般向けに書かれた統計の教科書を読みつつ、具体的な言語研究での統計の使用例と見比べながら学んでいくことになるだろう。
また、「より高度な内容」とひとくくりにしてしまったが、実際には簡単なものから難しいものまである。先日紹介した「言語研究者のための統計の学び方―基礎を身につける」という記事での基礎に比べれば高度というだけである。
学ぶ内容について具体的なキーワードを挙げよう。もちろん、研究の分野によって学ぶ内容が変わってくることは言うまでもない。
- 一般線形モデル/一般化線形モデル
- 分散分析 (ANOVA)
- 回帰
- 多変量解析
- 主成分分析
- 因子分析
- 判別分析
- クラスター分析
- ベイズ統計 [1]
これ以外にも学ぶ内容は色々とあると思う。だが、本職の統計学者になるというわけではないのだから、どこかで区切りをつける必要が出てくる。自分の必要に応じて、この記事で紹介する内容に触れていき、足りないところがあったら、あとから補充するというのがあるべき態度だと私は思う。
この記事の対象読者
この記事の対象読者としては、実際に言語研究を行い始めたばかりの人、具体的には卒論を書いている学部4年生や大学院に入ったばかりの修士課程の学生を想定している。
先日記した統計の基礎の勉強法は、学部3-4年生を想定していた。統計については全然分からないけれども、言語研究に関して多少のイメージが浮かんでいるような人を想定していたわけである。
今日の記事では、学部3-4年生が統計の基礎を勉強している内に進級・進学して学部4年生や修士課程の学生になったと想定している。おそらくこの時期になると、卒業論文などのための研究を通じて、自分が研究したいことがより明確になっているはずだ。基礎は誰にでも共通するのだが、より高度な内容になってくると、研究したい内容によって学ぶ内容が変わってくる。だから、研究したいことが明確になった時期に、はじめて基礎をこえた統計の知識を勉強するのが良いと思う。
卒論で統計的な処理が必要になるなら、学部4年生の内に、ここで紹介する勉強法のほんの一部でも学んでおけば、役立つかと思う。もし、自分の研究手法の中で、統計を余り使わないというのであれば、大学院に入ってからゆっくり学んで良い [2] 。
どんな手法があるか知ろう―より高度な内容に入る前に
これから学ぼうとする内容は結構難しく、いきなり理論的なことを勉強すると大変だ。まずはウォーミングアップとして、色んな統計手法を使った研究の例を見て、雰囲気だけでもつかんでおこう。なお、もし自分自身が統計を用いて研究するのでなければ、つまり、統計は他人の研究を見るときにだけ必要になるという人であれば、この節で触れた書籍を読んで雰囲気をつかむところで、統計の勉強をやめても良いと思う [3] 。
前回「言語研究者のための統計の学び方―基礎を身につける」という記事で紹介したStatistics in Language Studies という教科書や Quantitative Methods in Linguistics
という教科書の後半にも、分散分析 (ANOVA) や多変量解析などを扱った例が出ている。これらを読んで雰囲気をつかむこともできる。
コーパス関係で言えば、次の書籍を参考にすると良いだろう [4] 。
『言語研究のための統計入門』

- 石川慎一郎・前田忠彦・山崎誠(編) (2010). 『言語研究のための統計入門
』 東京:くろしお出版.
この『言語研究のための統計入門』には、主成分分析やクラスター分析などの多変量解析を利用した研究例が色々と紹介されている。理論的な背景はあまり記されていないので、この本だけでは統計手法の勉強にならないということに注意する必要がある。この本の方針は、「とにかく手を動かせ、残りはあとからついてくる」ということになると私は思う。まずは、この本の例に従って少し手を動かして、統計手法に関する雰囲気をつかもう。そして、この本を読み終わった後に、他の書籍などから知識をしっかり補充できれば完璧である。
なお、タイトルに「言語研究」とあるが、基本的にはコーパスを使用した研究を想定しており、実験などによる研究は想定外である。
また、この本は「統計入門」と書かれているが、本気で言語研究における統計の基礎を学ぼうとしている人 [5] には向かないと私は思う。その理由は以下の通り。
- 数式を使うことを避けているので、統計の理論的背景を学ぶには不足。
- データのコーディング方法とグラフの読み方・描き方の記載がほとんどない。前者は2ページを割くのみ。
- 統計処理に使うツールは基本的に Excel [6] 。
- ページ数の割に紹介している手法が多い。色々な手法を紹介している点は悪くないのだが、どうしてもその分だけ個々の手法の説明が薄くなってしまっている。
もちろん、この本は「ダメ」な本というわけではない。どんな本でも適切な場所で使わなければ意味がないというだけである。
『Rによるテキストマイニング入門』

- 石田基広 (2008). 『Rによるテキストマイニング入門
』東京:森北出版.
前半は、テキストデータをどのようにRに読み込ませるのかについて書かれている。後半には、読み込んだテキストデータをもとに様々な統計的分析を加えている。この本は、テキストマイニングという自然言語処理の一手法を紹介した書籍であるが、言語学、なかんずく日本語の研究にも応用できる。統計以外のことも色々勉強できるので、読んでおいて損はない。
Analyzing Linguistic Data

- Baayen, R. H. (2008). Analyzing Linguistic Data: A Practical Introduction to Statistics using R
. Cambridge: Cambridge University Press.
この本は、かなり難しい。4章までの内容は、比較的易しい内容で、前回「言語研究者のための統計の学び方―基礎を身につける」という記事で「基礎」とした内容が分かれば、大体理解することができる。5章はクラスター分析などの多変量解析の例が挙げられている。また、6-7章では、回帰や混合モデルの例が挙げられている。かなり難しい本なので、後で示す教科書などで高度な内容の統計知識を身につけた後に再度チャレンジしてみるのも良いと思う。
より高度な内容の統計知識を身につける
統計の基礎をしっかり勉強したら、さらにより高度な内容に進もう。前回「言語研究者のための統計の学び方―基礎を身につける」という記事で書いたように、高度な内容に進む前に、微積分や線形代数を勉強しておくと非常に役に立つ。
一般(化)線形モデル―複雑な要因を扱えるように
以前、「言語研究者のための統計の学び方―基礎を身につける」という記事で基礎で学ぶべきとした手法は、基本的には2つのものを比べるときにしか使えない手法 [7] であった。しかし、現実世界の現象は、さまざまな要因が絡み合っているわけで、2つのものを比較するだけでは足りない点がどうしても出てくる。
このため、3つ以上のものを比較するなど、より複雑な要因を統計的に取り扱えるようにしておきたい。複雑な要因を取り扱う手法には様々なものがあるが、まずは一般線形モデル (General Linear Model) というものを勉強しておくのが一番だろう。
実験系の言語研究では、分散分析 (ANOVA) という手法がよく出てくるが、この手法は実は一般線形モデルの一部だ。だから、一般線形モデルを勉強しておけば、分散分析も分かる。また、線形回帰や共分散分析 (ANCOVA) といったよく使われる手法も、一般線形モデルの一部である。結局、一般線形モデルを知っていると色んなことに応用できるのだ。
なお、一般線形モデルを拡張したものとして、一般化線形モデル (Generalized Linear Model) というものがある。字面をよく見れば分かるが、一般線形モデルから「化」という字が増えて一般化線形モデルになっている。詳しい紹介はしないが、一般化線形モデルは、一般線形モデルの適用範囲をより広くしたものと考えてくれれば良い。
一般線形モデルあるいは一般化線形モデルを学ぶ教科書を挙げておこう。以下に挙げるのは、いずれも言語研究者向けに書かれているというわけではない。

- Grafen, A. & Hails, R. (2002). Modern Statistics for the Life Sciences
. Oxford: Oxford University Press.

- グラフェン&ヘイルズ(著)野間口謙太郎・野間口眞太郎(訳) (2007). 『一般線形モデルによる生物科学のための現代統計学
』東京:共立出版.
まずは、GrafenとHailsの本から。元々は英文だが、上に挙げたように和訳も出ている。この本で一般線形モデルの内容がしっかり勉強できるはずだ。タイトルには“Life Sciences”や「生物科学」と書いてあるが、生物学の知識がなくても全く問題ない。統計ツールとしては、Minitab, SPSS, SASでの方法が記されている。Rでの方法は書かれていないのが残念。

- Dobson, A. J. & Barnett, A. G. (2008). An Introduction to Generalized Linear Models, Third Edition
. Boca Raton, FL: CRC Press.

- Dobson, A. J.(著)田中豊 等(訳)(2008).『一般化線形モデル入門 原著第2版
』東京:共立出版.
GrafenとHailsの本を終えて、さらに一般化線形モデルを勉強したいのなら、上に挙げたDobsonの本がある。原書は第3版まで出ているが、和訳は第2版のものなので注意。

- 豊田秀樹 (1994). 『違いを見ぬく統計学
』 東京:講談社.
実験系の言語研究を志している人は、分散分析をよく使うことになると思うので、上記の豊田の本のように分散分析を中心に扱っている書籍で知識を補充しておくのも良い。
その他の統計的手法
多変量解析やベイズ統計については、私があまり良い本を知らないので割愛する。言語研究者向けでなければ、色々な教科書が編まれているので、適宜自分の好みに合ったものを選べば良いと思う [8] 。
指標を知る
普通の統計学の教科書には出てこないが、言語研究において必要となる内容として、言語研究における「指標」という問題がある。統計学そのものにも相関係数のような指標があるが、それだけでは言語研究に足りないことがある。このため、言語研究特有の指標が色々と提唱されている。こういった指標を覚えておくと、統計的分析の幅が広がる。
こういった指標をまとめた教科書などはあまりない [9] ので、他人の研究で用いられている例などを見ながら、覚えていく必要がある。
事例1:コーパスにたくさん出てきても……
ある言語で「一般的でありふれた表現」を調べたいときがある。日本語を知らない人に日本語を教える場合は、日本語で「一般的でありふれた表現」から教えた方が効率が良いわけで、調べておくのには意味がある。単純に考えれば、頻度が高ければよく使われている表現と言えそうなものだが、実は頻度だけではうまくいかない。
例として、「国会」という表現と「昨年」という表現の一般的でありふれているかを考えてみよう。国立国語研究所が開発した『現代日本語書き言葉均衡コーパス』の検索デモを使って調べてみよう。書籍のデータだけに限ると、「国会」という表現は2146件ヒットする。これに対して、「昨年」という表現は1162件しかヒットしない。単に頻度しか見ないのであれば、「国会」の方がずっとよく使われているということになる。だが、日本語を話す人ならば、この結果に違和感を感じるであろう。特に政治の話が好きな人でなければ、「国会」よりも「昨年」の方が使う機会が多そうである。つまり、コーパスの頻度だけでは、言語感覚とずれが生じるのである。
なぜコーパスにおける頻度と実際の言語感覚にずれが生じたのであろうか。1つの理由として考えられるのは、今調べたのが書籍のデータに限られているということだ。書籍以外の書き言葉や話し言葉も含めれば、頻度がもう少し変わってくるかもしれない。
だが、もう1つ重要な理由がある。それは、表現の出現箇所の偏りである。少し考えてみれば分かるように、「昨年」という言葉はどんなジャンルでも出てきそうだが、「国会」という表現は、政治など限られたジャンルでしか出てこなさそうである。実際、『現代日本語書き言葉均衡コーパス』の検索デモでの「国会」の用例の2146件のうち、6割以上にあたる1365件は社会科学に関する書籍における例である。これに対して「昨年」は各種のジャンルで用例が見られ、最もよく見られる文学に関する書籍でも397件と全体の約3分の1を占めるに過ぎない。要するに、言語表現の中には、「国会」のように限られたところでたくさん使われ、他のところではあまり用いられない表現と、「昨年」のように広く薄く用いられる表現がある。つまり、「昨年」のほうが「散らばり」が大きいのである。
この例からも分かるように、実は、「一般的でありふれた表現」を考える際には、単純に頻度のみならず、「散らばり」も考えていく必要が出てくる。言語表現における「散らばり」の指標 [10] にはさまざまなものが提案されている。例えば、以下の論文を参照されたい。
- Gries, S. T. (2008). Dispersions and adjusted frequencies in corpora. International Journal of Corpus Linguistics 13 (4), 403-437.
事例2:実験に用いる単語の選択
言語実験を行うときには様々な要因を統制しなくてはならない。
よく言われるのは、被験者の統制である。例えば、被験者として男ばかりを選ぶと偏ってしまう可能性があるので、男女を半々にするように統制する。
被験者の統制の他に大事なのが、実験に用いる単語の選択である。例えば2種類の構文に対する反応を比べるときに、双方で用いられる単語の難易度があまりに違っていると差し支えが出てくる。例えば、能動態と受動態(受け身文)に対する反応スピードの違いを調べるときに、以下のような例文を挙げたらどうなるだろうか。
- 能動態の例:イヌがウサギを追いかけた。
- 受動態の例:狡兎が良狗に追いかけられた。
ここでは、いかにも受動態の例の方が難しそうで、反応時間が余計にかかりそうである。だが、受動態だから難しいと言うより、使っている単語が難しいからと言った方が正確であろう。それにもかかわらず、「一般的に受動態は能動態より反応スピードが遅い」と主張してしまったら、問題となるだろう。
これは極端な例であるけれども、実験に用いる単語の選び方が悪ければ、結果を歪めてしまうことがあるのだ。このため、一般的には、ある一定の指標を用いて使用する単語のレベルを同程度にする。
例えば、単語親密度という指標がある。これは、色々な人に色々な単語を見せてその単語にどの程度なじみがあるかを5段階や7段階評価したものである。例えば、NTTが作った日本語の単語親密度データベースでは、7段階評価の平均値をもって単語親密度としている。実験の際には、単語親密度がよく似た値を示す単語を選ぶようにすれば、問題が起きづらいというわけである。
事例3:音声学におけるフォルマント
音声学では、母音の特徴を知るために、フォルマントというものを計測する。ただ、人によって口の大きさ等が違うので、同じく「ア」や「イ」と発音しても人によってフォルマントが結構違ってきてしまう。
このために、個人差を捨象できるような標準化する手段が必要となる。つまり、研究する際には標準化の指標を知っている必要があるのである。なお、標準化の手法は1通りではなく、自らの目的等に応じて適切なものを選択する必要がある。例えば、NORMというウェブサイトでは、フォルマントの標準化手法を色々と紹介している。なお、NORMでは、素のフォルマントから標準化後の数値を出すウェブサービスも提供している。
限界を知る
統計を知らなくては話にならないが、統計ばかりやっていては言語研究はできない。統計的な手法をいくら知っていても、うまくいかないときはうまくいかない。専門の言語研究に対する深い洞察がなくては、うまく研究ができないのだ。
また、「統計的に良い」という手法が、現実にはうまく取れない場合がある。統計学的には、データを集める場合には偏らないようにランダムにするのが良いと言われている。しかし、言語データを収集する際に完全にランダムなデータを取るのは非常に難しい。例えば、話し言葉のデータを完全にランダムに集められるかと言えば、全くもって不可能である。話し言葉というものは、泡のように浮かんでは消えるものなので、意識的に録音などをしないかぎり、とどめることができない。そして、世界のあちこちで行われている会話などを、ランダムにつかまえるというのは到底不可能なのだ。だから、割り切って、手元のデータで勝負するしかなくなる。
こういった限界を踏まえたうえで、どこまでがんばれるかが勝負のしどころだ。
結果をどうアウトプットするか―論文での統計の報告
統計をしっかり勉強したら、あとは自分の研究にそれを生かしていこう。
何か研究をしたら最終的には論文という形で世に問うことになる。その際、どういう統計手法を用いたのか、そしてその結果はどのようなものだったのかということを書く必要が出てくる。このとき、問題となるのは、どこからどこまでを報告すべきなのかということである。単純に統計処理ソフトで出てきた結果を全部貼り付ければ良いというわけではない。第一、そうしたら紙幅が足りなくなってしまう。
論文で何を報告すべきかという問題の答えは、大体は論文のスタイルマニュアルに書いてある。例えば、心理学や言語学でよく使われる APA Manual でも、統計では何を報告すべきなのかについて事細かに書いてある。
一般の統計入門書にはあまり書かれていないのだが、統計的検定を行った場合、論文で「効果量」というものを報告するように求められる。これは結構重要なものなのだが、案外報告されていないことが多い。効果量の報告については、以下のように分かりやすい論文があるので、これを一読することをおすすめする。
- 水元篤・竹内理 (2008). 「研究論文における効果量の報告のために ―基礎的概念と注意点―」『英語教育研究』31, 57-66. (リンク先はPDFなので注意)
また、論文のスタイルマニュアルには、図表の体裁についても書かれている。こういったこともしっかり見ておきたい。
- ベイズ統計については、私が詳しくないので、この記事では特に触れないでおく。自然言語処理などではよく使われている。 [↩]
- とは言っても、修士の2年目は修士論文を書くのに手間をかけないといけないので、あまり後回しにしていると、勉強する時間が無くなってしまう。修士の1年目に、夏休みなどを使って勉強するのが良いかと思う。 [↩]
- 自分の研究で統計を用いる人は、雰囲気をつかむだけで満足してはいけない。 [↩]
- 実験系の言語研究における良い参考書については、私はよく知らない。もっとも、コーパス研究と違って、実験の場合、被験者を集めなければならないから、自分で再現するのが難しいという側面がある。 [↩]
- 例えば、先日の「言語研究者のための統計の学び方―基礎を身につける」という記事で、対象読者としたような人たち。 [↩]
- 初心者向けに取りかかりやすいように、Excelを選択したのだと思うが、研究を進めていくのなら、結局はRやSPSSを使うようになるので、そのときは他の本で、Rなどを勉強しなくてはならなくなる。 [↩]
- 例えば、t検定など。なお、基礎で学ぶべきとした、Χ2検定ならば、複数のものを比べるのに使える。 [↩]
- 統計のことに限らないが、よく分からない分野の教科書を買う場合は、有名な学術系出版社のものを買うのが無難。自分では評価のしようがないので、出版社の名声に頼るというわけだ。 [↩]
- 自然言語処理関係の入門書でコーパスなどにおける指標の例が出ていることがある。 [↩]
- 統計では、標準偏差や範囲といった散らばりの指標が用意されており、これを用いることもできる。 [↩]